Agustin Leon and Anup Raj Niroula, New York University
What is the central challenge your experiment investigates?
Computer-use agents are language model programs that operate a computer through the same channels a person does: controlling a cursor, typing into applications, and calling tools. Think of it like an assistant that can organize your Notion notes, update a GitHub issue, or manage your calendar without needing step-by-step instruction. Through Model Context Protocol (MCP), an open standard released in late 2024, agents can perform actions with specific applications in a consistent way. Adoption of MCP has been rapid: by the end of 2025, PulseMCP, a popular directory of MCP servers, had already tracked over 15 million downloads and more than 6,000 MCP servers.
This ecosystem is growing faster than our ability to evaluate it, and we still do not have solid answers to basic questions such as how different agent designs compare, which tasks are hardest, or where agents tend to fail. Answering those questions depends on benchmarks that are rigorous and reproducible, and this is where the current generation of MCP benchmarks falls short. Most of them rely on commercial language models accessed through external APIs. Those models get deprecated, their behavior can change without notice, and when that happens, benchmark results become impossible to reproduce. We set out to build a benchmark that avoids these problems.
How is your research addressing this challenge?
OpenMCP is our contribution: an open-source, fully self-hosted benchmarking harness for MCP-enabled computer-use agents. It follows a "Bring Your Own" principle, where researchers bring their own models, tasks, MCP servers, and infrastructure, and the harness handles scheduling, isolation, evaluation, and telemetry.
Evaluating a computer-use agent is a multi-part problem. It requires infrastructure to run the language model powering the agent, an evaluator to determine whether a task was actually completed, a task suite worth running, and a place for the agent to operate: typically a virtual desktop with real applications installed and MCP servers exposed. OpenMCP brings these pieces together behind a single configuration file. Additionally, by building on a self-hosted model, we are able to overcome the challenge of non-reproducibility of previous benchmarks. Future OpenMCP users will be able to reproduce our experiments and compare their own results in a reliable way, without worrying about models changing or being deprecated without warning.
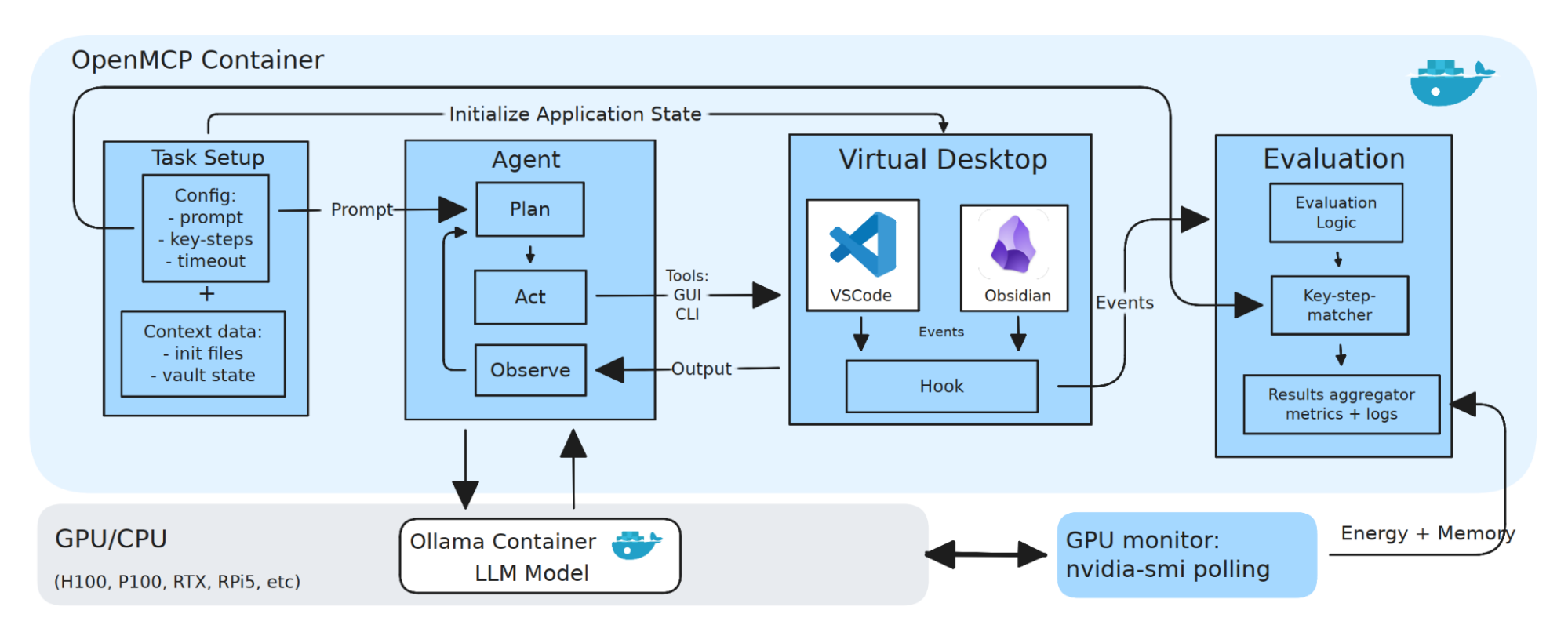
The architecture has four components. The agent itself implements a Plan-Act-Observe loop: it queries a locally served language model to decide on an action, executes that action against the environment, observes the result, and repeats — with actions falling into one of three categories (MCP tool calls, GUI operations on the virtual desktop, or shell commands). The agent acts on a task suite, a set of concrete instructions like creating a note in Obsidian, changing the tab size in VS Code, or committing a change from a Git workspace, each paired with verifiable key steps and a handler script that defines success.
All of this activity happens inside a playground: a containerized Ubuntu environment with the target applications installed and the MCP servers wired in. An evaluator oversees the whole process — it runs the agent, detects task completion through deterministic checks tied to internal application events, classifies failures into categories (planning loops, hallucinated tool calls, partial completions, timeouts), and collects infrastructure telemetry along the way, including GPU utilization, memory, power draw, and total energy per task.
How do you build your experiment on Chameleon?
OpenMCP is fully containerized. Once an instance is provisioned, a complete experiment launches from a single configuration file with a handful of commands, and the whole setup is published as a Trovi artifact so the environment can be reproduced on Chameleon without manual reconstruction.
Running experiments is a straightforward process. Once the instance is provisioned, users modify one single configuration file, where they define the parameters for their experiments — selecting models, applications, agent runtime types (what the agent is allowed to do), and timeout limits, among others. Once the configuration file is ready, OpenMCP automatically brings up the necessary services according to the user's specifications and starts the experiment. During the experiment, OpenMCP collects rich data for each task: metadata, metrics, raw events (the steps taken by the agent), and GPU hardware telemetry. Users can access this data as structured JSON files, ready to be processed for analysis.
Our experiments ran primarily on KVM@TACC and CHI@TACC, with edge runs on CHI@Edge using a Raspberry Pi 5. On the KVM side we relied heavily on volume storage to keep a persistent development environment across sessions, which turned out to be essential over the six months the project lasted. Chameleon's reservation model also helped: knowing the hardware availability allowed us to schedule long experiment runs without guesswork.
What features of the testbed did you need in order to implement your experiment?
Three features of Chameleon were central to this project. The first was hardware diversity: we ran experiments on H100, RTX 6000, P100, V100, a CPU-only host, and a Raspberry Pi 5 at the edge. The ability to evaluate the same agent across that range — from a high-end datacenter GPU down to an edge device — is not something we have found elsewhere, and it made direct cross-hardware comparisons of energy, latency, and task success possible under identical task definitions. The second was easy provisioning through Trovi: packaging the full environment as an artifact keeps the barrier to reproduction low, so a user can clone it and be running the same experiments we did shortly after, without rebuilding the setup by hand.
The third, and the one that shaped our day-to-day workflow the most, was the KVM@TACC H100 instances. They provision in a few minutes, compared to roughly 30 minutes for baremetal, and they support persistent volume storage — which is critical for long-running development where rebuilding the environment repeatedly is not practical, and taking snapshots is not feasible. Their attached storage is also sufficient to work with very large models, including the Qwen3-VL 235B variant we benchmarked. Without Chameleon, a project of this shape would have been significantly harder to execute: direct bare metal access and reproducibility guarantees are difficult to obtain in commercial clouds, and the cost at this scale would likely have been prohibitive.
Can you point us to artifacts connected with your experiment?
Everything from the project is openly available, including artifacts, codebase, and data.
- Trovi artifact: https://trovi.chameleoncloud.org/dashboard/artifacts/31fc62a4-1996-4719-957e-4c1b4e47b1b6
- OpenMCP codebase: https://github.com/AguLeon/OpenMCP
- Chameleon User Meeting 2026 slides: https://docs.google.com/presentation/d/1nqtelJHctmnP14360qowXBY6zpfdqBFxY6aXLzmaUQ0/edit?usp=sharing
- Upcoming EuroMLSys publication: Agustin Leon, Anup Raj Niroula, and Fraida Fund. 2026. OpenMCP: an open-source self-hosted benchmarking harness for MCP-enabled computer use agents. In The 6th Workshop on Machine Learning and Systems (EuroMLSys '26), April 27–30, 2026, Edinburgh, Scotland UK. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3805621.3807649
Tell us a little bit about yourselves

We are both Computer Engineering master's students at NYU. Our research interests focus on machine-learning systems, and particularly on the space between "lab ML" — where the model is the only variable that matters — and production ML pipelines that have to be reliable, efficient, and deployable in real settings. Outside of research, we enjoy hiking in the outdoors, and discovering new streets and alleys around New York City.
Most powerful piece of advice for students beginning research?
It doesn't need to be pretty. It needs to work. When you're starting research, it's easy to fall into the perfectionist trap of trying to make code, ideas, and notes flawless from the start. That mentality tends to get you stuck and slows progress. Focus on getting something — anything — done, even if it isn't pretty. Research is an iterative process. You will always have opportunities to reflect, refine, and improve your work along the way. Progress matters more than polish at the start.
How do you stay motivated through a long research project?
Staying consistently motivated across a long project is not really possible, at least not in our experience. What matters is to keep moving when motivation is low. If you feel stuck in a rut, take a break, get some fresh air. Coming back with a clear mind often makes a problem look smaller than it did before, and we have lost count of the number of times a short pause has helped us work through something that seemed impossible an hour earlier.
Then try again. And again. If you focus on the next step and stay consistent, you will make progress, and one day, before you realize it, the project will be done. The satisfaction at the end is hard to match. "Just keep swimming."