Software upgrades are supposed to be routine. In a large data center, thousands of distributed-system upgrades can happen in a single day, each one quietly swapping in new code and migrating the system's stored state from the old version's format to the new one's. Most of the time, no one notices. But when that migration goes wrong, the results can be spectacular — and a team at Purdue University has built a tool, called UpFuzz, designed specifically to catch the failures before they reach production. The work earned the Community Award at NSDI '26, USENIX's flagship networked-systems conference as an outstanding paper with publicly available code and data.
When an upgrade goes wrong
The bugs UpFuzz targets are a class its authors call data format incompatibility (DFI) bugs. They occur when a newly upgraded version of a system reads data that the old version wrote to disk, but the format of that data — how it is structured and interpreted in memory and on storage — changed across versions in a way the upgrade logic didn't fully handle. The new version then misinterprets perfectly valid old data, and the consequences cascade: crashed clusters, corrupted records, silently lost data, and large-scale service outages.
This is not a niche concern. Prior research has found that data format inconsistencies account for nearly two-thirds of distributed-system upgrade failures. And the real-world track record is sobering. The paper points to a 2025 Google Cloud outage that affected roughly 1.4 million users, traced to an inconsistency in a policy data structure between old and new versions of a control service, and to the 2024 CrowdStrike incident that crashed millions of systems worldwide — also rooted in a format inconsistency surfacing during an update.
Why these bugs slip through
Part of what makes DFI bugs so persistent is that they are mostly discovered after release. There is surprisingly little automated testing built specifically for the upgrade process — most upgrade tests are written by hand and cover only a narrow set of scenarios. The closest prior work, a tool the same Purdue group built earlier (DUPTester), automated some upgrade testing by repurposing existing stress and unit tests, but inherited the limited coverage of those hand-written tests.
The obvious next step — fuzzing, which generates and runs huge numbers of tests to shake out edge cases — runs into a hard wall. A single upgrade operation can take tens of seconds or even minutes to complete, because the system has to flush data, shut down cleanly, reinitialize, reload configuration, and re-establish cluster membership. Traditional fuzzers depend on running enormous numbers of cheap tests quickly; when every test can carry the cost of a full upgrade, brute force becomes hopeless. The real problem is figuring out which tests, out of an effectively infinite pool, are actually worth the expense.
A fuzzer that knows where to look
UpFuzz's central insight is that DFI bugs come from a specific, identifiable slice of a program's state. A bug can only appear when some piece of data is written to disk by the old version, read back by the new version, and the format of that data changed between the two. The team calls this slice the Transitively Persisted State (TPState): the subset of program state that ends up persisted to storage — directly, or indirectly through chains of in-memory copies — and is later read after the upgrade.
Rather than rewarding a fuzzer for exploring new code or new states indiscriminately, which drowns instantly in the state space of a real system, UpFuzz selectively monitors these transitively persisted states, infers the data-format properties that govern how they are serialized and deserialized, and prioritizes the states whose underlying class definitions actually changed across versions. It also lets the fuzzer skip the expensive upgrade step for tests that don't look promising, concentrating its limited budget where a cross-version bug is most likely to hide. The result, according to the authors, is the first feedback-driven fuzzing engine built specifically to test cross-version data-format compatibility during distributed-storage upgrades.
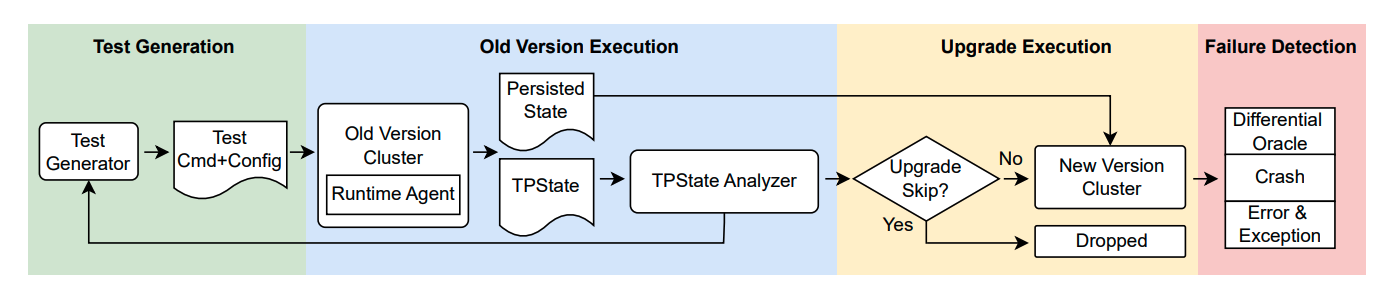
The UpFuzz pipeline. It generates tests and runs them against an old-version cluster while a TPState analyzer inspects the state being persisted, decides whether each test is worth the cost of a full upgrade (skipping the unpromising ones), then upgrades and checks the new-version cluster for failures using a differential oracle, crashes, and error logs.
What it found
The team applied UpFuzz to three of the most widely deployed open-source distributed storage systems: Apache Cassandra (a peer-to-peer database), HDFS (the Hadoop distributed file system), and HBase (a master-worker database). These are mature, heavily tested systems that historically see only about one or two data-format incompatibility bugs reported per year.
UpFuzz found 15 previously unknown DFI bugs across them. Eight have already been confirmed by the projects' developers and three have been fixed. Six of the bugs crash the cluster outright, and four cause data loss or corruption. Notably, 7 of the 15 could only be discovered once UpFuzz's transitively-persisted-state analysis was switched on — they were invisible to a strong baseline built from conventional state-of-the-art fuzzing techniques. Against that baseline, UpFuzz reached the same incompatibility-related states roughly 4.7 times faster. Counting the additional upgrade and single-version bugs it surfaced along the way, the tool has uncovered 38 previously unknown bugs in total.
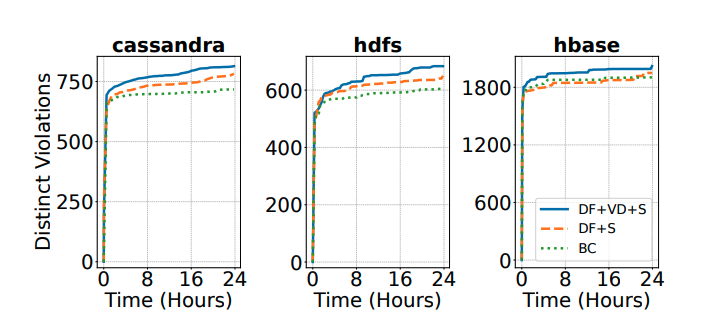
Distinct incompatibility-related states discovered over a 24-hour run on Cassandra, HDFS, and HBase. UpFuzz's full configuration (DF+VD+S, the solid blue line) surfaces more of these states — and reaches them faster — than a conventional branch-coverage baseline (BC, the dotted green line).
Open by design
What sets UpFuzz apart for the broader community is not only what it found but how openly it was released: the fuzzing engine, the analysis, and the supporting data are all publicly available on GitHub. That openness is recognized directly by the field — UpFuzz received the NSDI '26 Community Award, which USENIX presents to outstanding papers whose code and/or dataset is made publicly available by the final paper deadline. For a research area where reproducibility is hard — the bugs are rare, the systems are large, and the experiments are long-running — a fully open, runnable artifact is a meaningful contribution in its own right. The code lives at github.com/zlab-purdue/upfuzz.
Built on bare metal
Hunting these bugs is not a single-machine job. Each target system runs as a real multi-node cluster — a single node for Cassandra and three nodes each for HDFS and HBase in the published setup — and the evaluation packed several such clusters onto each physical machine to run tests in parallel. Because every test can trigger a full upgrade, the team ran sustained campaigns: each configuration was fuzzed for 24 hours and repeated three times, across multiple version pairs and analysis settings. That is exactly the kind of long-running, multi-node, bare metal workload that is awkward and expensive to reproduce on a shared commercial cloud, where dedicated hardware and full control of the software stack are hard to come by.
To run that evaluation, the authors credit Chameleon Cloud — alongside CloudLab — for providing the computing infrastructure behind the project. Bare metal testbeds like these give researchers the isolated, reconfigurable, multi-node environments that systems work of this kind depends on, and they make it possible for others to rerun the experiments on comparable hardware rather than approximating them.

Ke Han, the paper's lead author.
Learn more
- Paper: Ke Han, Sruthi P C, Yayu Wang, Yaoxu Song, Bishal Basak Papan, Junwen Yang, Pedro Fonseca, and Yongle Zhang. "UpFuzz: Detecting Data Format Incompatibility Bugs during Distributed Storage System Upgrade." In the 23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI '26). usenix.org/conference/nsdi26/presentation/han
- Code: github.com/zlab-purdue/upfuzz
- The team: The work comes from the labs of Yongle Zhang and Pedro Fonseca at Purdue University, with collaborators at the University of British Columbia and Meta.