Every time you run a search query, stream a video, or send a message, a data center somewhere is burning energy to make it happen. Keeping those data centers fast and efficient is a constant engineering challenge—and one of the most powerful tools available is profile-guided optimization (PGO): using data about how an application actually runs to reorganize its binary code for better performance.
The catch? Profiling takes time, and software doesn't stand still. By the time engineers have collected a useful profile and applied it to their code, they're often already shipping the next version of the software. According to recent work from Google and Meta, 70–92% of profile samples can become stale within a week of a new release—meaning they no longer accurately map to the code they were meant to optimize. The result is a significant, persistent performance gap in some of the most critical software on the planet.
Tawhid Bhuiyan, a Ph.D. student at Columbia University working with Professor Tanvir Ahmed Khan, set out to close that gap. The result is Wax, a novel technique that recovers the vast majority of performance benefits from stale profiles—without needing to re-profile the fresh binary.
Why Stale Profiles Are So Hard to Use
Profile-guided optimizers like BOLT work by identifying "hot" functions and basic blocks—the parts of the code executed most frequently—and packing them together in memory. This shrinks the code footprint, reduces instruction cache and TLB misses, and can deliver end-to-end speedups of several percent, worth millions of dollars at data center scale.
But to use a stale profile on a fresh binary, you first have to figure out which parts of the old binary correspond to which parts of the new one. This mapping problem turns out to be surprisingly difficult.
Existing approaches tackle it at the binary level, comparing function names and hashing basic-block instruction sequences. The trouble is that C++ binaries are messy. Function names—or "mangled names"—encode namespaces, parameters, and compiler-generated suffixes, all of which can change between versions even for logically identical functions. And basic-block hashes break the moment a single instruction is added, removed, or reordered, which happens constantly as developers fix bugs and add features. The state of the art leaves up to 33.9% of function samples and 34.8% of basic-block samples unmapped—and those unmapped samples represent lost performance potential.
A Different Approach: Look at the Source
Wax's key insight is that the binary isn't the only available source of truth. Data center optimization pipelines already generate and store debug information alongside binaries—metadata that links binary instructions back to the source files and line numbers that produced them. And the source code itself is always available. Why not use both?
Wax works in three coordinated steps:
- Source Mapping: Wax first maps source files from the stale version to the fresh version, then maps individual source lines by comparing their content—exact matches first, then fuzzy matching using Levenshtein similarity for lines that changed slightly.
- Function Mapping: Using the source file mappings as anchors, Wax compares function names component by component—namespace, basename, parameters, and compiler suffix—rather than treating the mangled name as a single opaque string. This allows Wax to correctly match functions whose names changed in predictable ways across versions.
- Basic-block Mapping: Rather than hashing entire basic blocks, Wax partitions assembly instructions by their mapped source locations. Within each partition, it maps instructions by comparing opcodes and operands, then aggregates those instruction mappings into basic-block mappings using similarity scores and control-flow neighbors as tiebreakers.
The result is a much more robust mapping that survives the kinds of source-level changes that defeat binary-only approaches.
Testing on Chameleon
To evaluate Wax rigorously, the team needed server-class hardware with support for Intel's Last Branch Record (LBR) profiling technology—the same mechanism used by companies like Google and Meta for continuous production profiling. Chameleon's bare-metal nodes at TACC, specifically machines with Intel Icelake Platinum 8380 CPUs, provided exactly that environment.
The experiments spanned five widely-used open-source applications with large code footprints: gcc, clang, mysql, postgresql, and mongodb. For each application, the team compiled a "stale" version and a "fresh" version, collected LBR profiles from both, and used BOLT to optimize the fresh binary under three conditions: with its own fresh profile (the theoretical best case), with the stale profile mapped by the prior state-of-the-art technique, and with the stale profile mapped by Wax. Each experiment was run at least five times to ensure statistical reliability.
Results
The numbers tell a clear story. Optimizing with fresh profiles delivers speedups ranging from 7.64% (postgres) to 38.45% (mongodb). The prior state of the art captures only a fraction of those gains when using stale profiles. Wax does substantially better:
- gcc: 8.72% speedup with Wax vs. 3.90% with prior work (fresh profile: 11.72%)
- clang: 18.21% vs. 15.98% (fresh: 19.63%)
- mysql: 26.46% vs. 18.60% (fresh: 32.63%)
- postgres: 5.76% vs. 4.56% (fresh: 7.64%)
- mongodb: 24.89% vs. 17.81% (fresh: 38.45%)
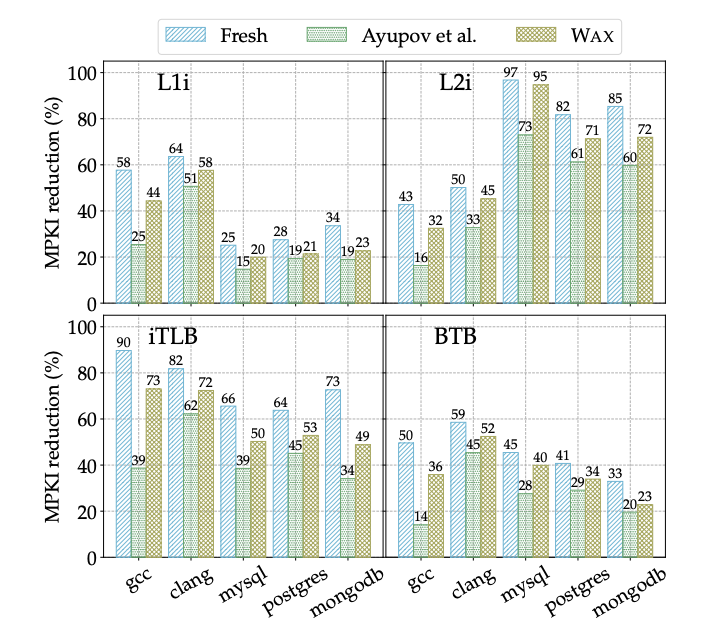
Across all five applications, Wax achieves 65–93% of the speedup that a fresh profile would deliver, and outperforms the prior state of the art by 1.20–7.86 percentage points. The improvements carry through to microarchitectural cache miss rates as well: Wax reduces L1 and L2 instruction cache misses, iTLB misses, and branch target buffer misses more effectively than any prior technique.
The results hold up across diverse workloads and across both minor and major version gaps. When the researchers tested Wax against eight different MySQL query types, it consistently outperformed the prior state of the art for every single workload. And as profile staleness increased with wider version gaps, Wax's advantage grew larger—exactly the behavior you'd want in a real deployment environment where software evolves rapidly.
As a final stress test, the team compared Wax against OCOLOS, an online system that sidesteps the staleness problem entirely by profiling and optimizing a running binary in real time—meaning it uses a fresh profile by definition. Wax, operating offline with a stale profile, still outperformed OCOLOS even after OCOLOS finished its optimization pass. The reason: OCOLOS leaves function pointers pointing to unoptimized code, a limitation that Wax doesn't share.
Looking Forward
Wax is implemented in roughly 2,240 lines of Python and integrates cleanly into standard PGO pipelines. It requires only the debug information that optimization systems like AutoFDO already generate and retain—no new instrumentation, no changes to the profiling infrastructure. The team has also demonstrated that Wax's approach extends beyond BOLT: applying the same mapping technique to Propeller, Google's re-linking optimizer, produced a 6.44% speedup for clang compared to 5.38% with the prior state of the art.
Profile staleness is an unavoidable feature of fast-moving software development. Wax demonstrates that it doesn't have to be a performance ceiling.
Publication: This work was published at ASPLOS '26: Wax: Optimizing Data Center Applications With Stale Profile. DOI: 10.1145/3779212.3790248
Code: https://github.com/ice-rlab/wax
About the Author
Tawhid Bhuiyan is a Ph.D. student at Columbia University, advised by Professor Tanvir Ahmed Khan. His research focuses on profile-guided optimization, microarchitectural efficiency, and compiler systems for data center applications. For more details, visit his homepage.